
KOTARO NUKAGA(天王洲)の拡張移転に伴い開催される「AIと生成芸術」をテーマにした個展「Rhizomatiks Beyond Perception」。
ライゾマティクスは本展のために、既存の基盤モデルを一切使用せず、独自に作成した画像のみをゼロから学習したAIモデルを新たに開発しました。また、本展を通して、誰もがAIを使って画像を生成することができる現代において、改めて「生成される画像の価値とは何なのか?」を問いかけます。
「Rhizomatiks Beyond Perception」
会期: 2024年6月29日(土) 〜 10月14日(月・祝)
開廊時間: 11:00 – 18:00 (火-土)
※日月祝休廊
※8月11日(日) – 8月19日(月)夏季休廊
※10月13日(日)・14日(月)開廊
会場: KOTARO NUKAGA(天王洲)
〒140-0002 東京都品川区東品川1-32-8 TERRADA Art Complex II 1F
*本展では、AIモデル(販売価格550万円+税/ 5エディション)および同モデルで生成したアクリルパネル(販売価格30万円+税/30エディション)を販売。
*本モデルのご購入者にはモデル使用ライセンスをお渡しします。その内容に基づき、ライゾマティクスの画像のみを学習した本モデルを使用し、ご自身で画像を生成し、商用非商用問わずご利用いただけます。また、ご自身の作品や許諾を得た作品であれば、本モデルに追加学習することも可能です。
技術解説
Rhizomatiksの映像作品のみを学習した画像生成AI「Beyond Perception Model」を作成した。本ページでは、この「Beyond Perception Model」をどのように作りあげたかについて解説する。
1.データセット作成
学習を行うために、まずRhizomatiksが独自に作成し著作権を保有する映像素材の収集を行った。過去作成した映像と、今回展示のために作成した映像を合わせ、合計108個の映像素材を準備した。各映像素材は30秒〜4分程度の長さを持ち、それらをフレーム単位で静止画に変換することで、合計約17万枚の静止画を学習データとして準備した。
次に、各画像についてのラベリング(アノテーション)を行った。
その際、ほとんどの映像が具体的な物体を伴わない抽象的なグラフィックであることから、各映像に適切なキャプションを付与することが困難であると判断し、代わりに、各映像ごとにユニークIDを設定し、画像IDペアのデータセットを作成した。
これは例えば、映像1から変換した画像1~1000にID1、映像2から変換した画像1001~2000にID2という分類ラベルを付与するということである。
そのため、今回のBeyond Perception Modelは、テキストプロンプトから画像を生成するモデルではなく、各映像ごとのユニークIDとその強度を混ぜ合わせて画像を生成する「クラス条件付け」モデルとして学習を行うこととなった。そのため、本モデルではCLIP Text EncoderなどのText Encoderは使用していない。

学習した画像(一部)
2. モデル構造の決定
本モデルは、自社データのみでフルスクラッチ学習することと、Jetsonなどの小型の組み込み型デバイスで画像生成処理を動作させることを念頭に置き、既存の画像生成AIと互換性のない、独自の小規模なパラメータ数の潜在拡散モデルを設計した。
そのベースのアルゴリズム自体は、2022年以降に世間で注目された多くの画像生成AIでも使用されてきた拡散モデル[1]を発展させた潜在拡散モデル[2]を採用している。拡散モデルとは、学習時に学習画像にノイズを少しずつ加えていき、最終的に純粋なガウシアンノイズの画像に変化させる拡散過程を行うことで、ガウシアンノイズの画像から少しずつノイズ成分を取り除く逆拡散過程を学習していくモデルのことである。
また、前述の通り「Beyond Perception Model」は、生成する際の入力はテキストプロンプトではなく、映像のユニークIDと重みの数値の組み合わせとなっている。それらを直接指定することで、学習データの映像の成分をミックスした画像を生成することができる。さらに、生成ステップごとに個別に映像のユニークIDと強度を複数指定することで、より多様な出力を得ることができる。たとえば、今回の展示では全て50ステップで画像生成を行っているが、1~20ステップはID 8を強度0.8、10~30ステップはID 35を強度1.2、10~50ステップはID 78を強度1.0といったように指定している。
今回のように全体の学習データが少ない状況においては、このようなクラス条件付けのモデルの方がより良好な学習結果を得ることができる。
本モデルの学習はU-NetとVAEという2つのモジュールから構成されている。
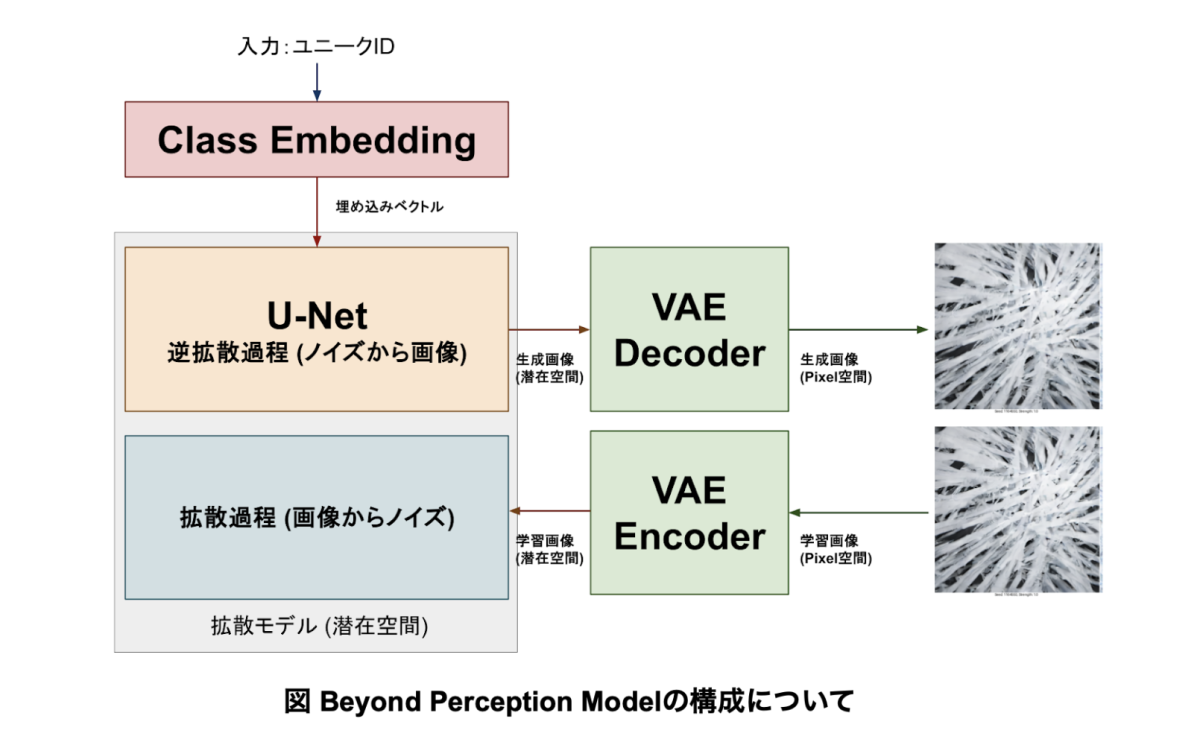
U-Netは、ノイズ画像から小さい画像を生成する、画像生成のコアモジュールである。U-Netで構図や描写対象などの画像を構成する多くの要素が決定する。
VAEは、画像のピクセル表現と、よりコンパクトな潜在表現を相互に変換するためのモジュールである。生成時は、潜在空間からピクセル空間への変換を行う(Decoder)。学習時は逆にピクセル空間から潜在空間への変換を行う(Encoder)。
3. 学習
学習自体はVAE→U-Netの順番で行った。
VAEの学習も、1章で説明したRhizomatiks17万枚のデータセットを用いて、フルスクラッチ学習を行った。VAEの学習は画像をエンコード(圧縮)した潜在表現を得るための学習であり、画像をエンコード(圧縮・ダウンスケール)して、デコード(展開・アップスケール)した時に、デコードされた画像の元画像との誤差が最小になるように学習が進行する。結果として、データセットの画像を効率よく圧縮できるエンコーダー・デコーダーを得ることができる。
VAEの学習では、通常、知覚損失としてLPIPS[3]が採用されることが多いが、LPIPSもニューラルネットワークであり、ライセンスが不明瞭な学習データで学習されていることからLPIPS損失は使用せず、代わりに、数式のみで表現でき、学習データのライセンスの懸念が発生しないWavelet損失[4]でVAEの学習を行った。
U-Netも、「Rhizomatiksが独自に作成し著作権を保有する映像から作成した合計17万枚の画像IDペアのデータセット」を用いて、フルスクラッチで学習を行った。
U-Netの学習は、256×256ピクセルという低解像度で学習を開始し、徐々に高解像度に移行するような形で学習を行い、最終的には896×512ピクセルでの画像生成が可能となった。これらの学習プロセスでは、パラメータを微調整しながら複数回の学習を実行した。そして、合計8回の学習プロセスをつなぎあわせることで、最終的な「Beyond Perception Model」が完成した。
4. リファレンス
[1]
“Denoising Diffusion Probabilistic Models”https://arxiv.org/abs/2006.11239
[2]
“High-Resolution Image Synthesis with Latent Diffusion Models”https://arxiv.org/abs/2112.10752
[3]
“The Unreasonable Effectiveness of Deep Features as a Perceptual Metric”https://arxiv.org/abs/1801.03924
[4]
“Wavelet Loss Function for Auto-Encoder”https://ieeexplore.ieee.org/document/9351990