
「recursive」は、KOTARO NUKAGA(天王洲)で「AIと生成芸術」をテーマとした「Rhizomatiks Beyond Perception」にて発表した、ライゾマティクスが独自に作成した約17万枚の画像のみで学習したAIモデル《Beyond Perception Model》を発展させ、「AIの再帰的な自己学習と創造性の進化」をテーマに探求したプロジェクトです。
本展では、会場となった表参道の交差点に大型LEDと、LEDの画面そのものを映すカメラを設置。LEDはAIモデルが生成した結果を表示し続け、AIモデルはカメラに映し出される自己の姿を用いて、モデル自体を再帰的に学習させ続ける様子は、さながら通常のインタラクティブ映像やフィードバック現象の展示のように見えますが、実態は後述の通りそれとは異なっています。
過去の研究では、AIがAIから作った画像から学習すると、多様性に悪影響を及ぼし、品質が低下することが報告されており、進化するのではなく、逆に崩壊するリスクが指摘されています。
参考 – AIが生成した画像を用いて別の生成モデルが学習する際の影響についての論文: https://arxiv.org/abs/2307.01850
この展示では、カメラに映し出される来場者の姿を含む実世界のデータを取り込むことで、そのリスクを軽減する試みを行いました。同時に、カメラやディスプレイの特性、環境光の変化などの不確定要素がAIの学習に与える影響も観察対象となっています。
展示館内では、そのAIモデルが再帰的にどのような学習過程を辿るのか観察できるようになっています。前述のとおり、AIモデルが自身の姿で学習を続けていくと崩壊する可能性がありますが、本作品ではAIの自己学習のループに人や環境光が介在することでモデルが崩壊することを回避し、単なるフィードバックや機械学習を超えた、創発的な表現の実現を目指しています。本展はその全容を作品として展示するというチャレンジングな試みになりました。
この学習プロセスには、カメラに映る自身の姿も影響を与える可能性を秘めています。自分の存在が、AIの創造性にどのような影響を与えるのか。Rhizomatiksが切り拓く、AIと人間の共創による新しい芸術体験。それが「recursive」です。
展覧会名: Rhizomatiks「recursive」
キュレーター: 、長谷川祐子(金沢21世紀美術館館長)
会期: 2024年9月14日(土) – 10月3日(木)
時間: 10:00 – 20:00
会場: OMOTESANDO CROSSING PARK
主催: anonymous art projent
協力: KOTARO NUKAGA
本展実施によせて:キュレーター 長谷川 祐子(金沢21世紀美術館館長)からのコメント
表参道にAIを放つ、あどけない観照。再帰性と偶然性
「recursive」はKOTARO NUKAGA(天王洲)で開催中の「Rhizomatiks Beyond Perception」のスピンアウトであり発展系のプロジェクトである。東京の感性情報がもっとも洗練された形で集結する、表参道の交差点にAIを放つ、という試みである。AIを主体性のあるエージェントや擬人化することで人間との関係を検証することは、過渡期にあるテクノロジー関係者にとって大きな関心事である。
AIがつくりだした画像を同じモデル(本人)に再学習させるというライゾマの試みはラデイカルであると同時に啓発的である。AIに自己学習させると劣化が起こりモデルが崩壊するリスクがあることは知られている。recursive では表参道のパブリックスペースに、LEDスクリーンとそこから5m離れた地点にカメラが設置されている。ライゾマは、その間に「偶然的」に介入してくる人やモノ、光や気象の変化などの実世界のデータを取り込むことで、崩壊のリスクをかわし、単なる自己学習を超えた創発的な表現を試みている。フィルターバブルの中にとらえられ、自己撞着化しがちな我々の現在に対する警告であると同時にこれを回避するための提案ともいえる。
AIモデルが生成したイメージAを外部情報として見るとき、そこに自分の創造物Aを見ている観客の姿が同時に含まれてくる。ドイツの現代作家トーマス・シュトルートの美術館の観客と作品を一緒に撮ったシリーズ、そこには作品を鑑賞する空間としての美術館空間の政治性、制度性が写しこまれている。
しかしAIモデルにとって情報データのヒエラルキーはないため、スクリーンに反射する太陽の光もその前に立つ人の姿も同じ偶然に介入した情報として処理される。0度の視点でとりこまれたデータがイメージAと混ざり合うことで新たな画像が生成される。
人間は自己の記憶に新たな体験を通して弁証法的、思弁的フィードバックを重ねながら認識を拡張する。展示において出色なのは、あどけないほど無防備に外界の刺激に対して開かれたAIと、その取り込みと生成のプロセスをトレーニングバッチとして見せるライゾマの情報処理の感度と美学である。
スクエアのモニターにカメラがとらえたライブ画像が、そしてその隣にはそこから生成される画像が並ぶ。プロセスを分割してみせるトレーニングバッチのむかって左のモニターにおいては直近1時間の学習素材がみせられている。偶然通りかかった人の姿、それが生成過程にとりこまれていくそのプロセスの明快さと美しさ。右はノイズの誤差であり、多様なピクセルが絡まりあいながらAIがイメージAと偶然性の混合物からより正確な画像のゴールにたどりつくまでの 試行錯誤の過程をバイブなノイズの画面として見せている。
生成画像というゴールだけではなく、その過程をどのように見せるのか。自分の創造物とそれをみる観客、周辺をとりまく光やそのほかの事象をデータとして再起と偶然による創造過程を提示したこのプロジェクトは、AIのあどけない観照と、ゴールにむけての緻密な試行錯誤がもたらす未知の可能性を示している。
展示解説

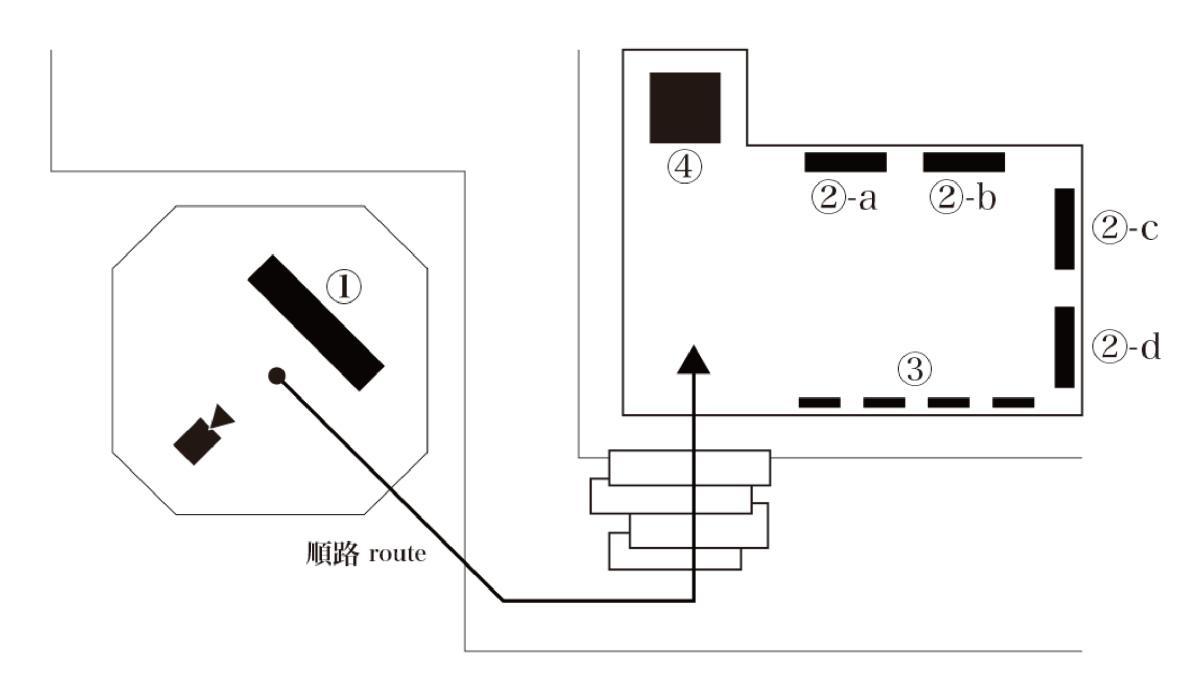
① recursive visual

「Beyond Perception Model」をベースに「AIの再帰的な自己学習と創造性の進化」をテーマとして独自素材で学習したAIモデルが生成するビジュアル表現を再生している。
本作でも、ユーザーはこのモデルを使って独創的な画像を生成し、鑑賞することができる。さらに、専門家や技術者はこのモデルを使用して、新たな作品やサービスを設計することができ、作品所有者にはそのライセンスも与えられる。
② Real-Time Training Process

本エリアでは、カメラを用いてAIがリアルタイムに学習している様子を、4つのプロセスで観察することができる。
②-a:Visualization of training data(学習データの可視化)
AIがミニバッチ学習という手法でデータを取り込みながら学習している様子を可視化している。ミニバッチ学習とは、データを一度に大量に処理するのではなく、小さなグループ(バッチ)ごとに分割して学習する方法である。この手法によって、効率的に計算が進み、メモリの使用量も抑えられるため、現在のほとんどすべてのAIの学習で採用されている手法である。
表示されている画像群は、現在AIが実際に使用しているミニバッチそのものである。リアルタイムでAIが学習しているのは、カメラで取得した最新の画像に加えて、直近1時間以内に取得した画像もランダムに混ざって使用されている。これにより、AIがどのようなデータを処理しながら学習を進めていくかを視覚的に追うことができる。
②-b:Visualization of learning progress(学習経過の可視化)
この学習は、潜在拡散モデル(Latent Diffusion Model, LDM)を使ったものである。潜在拡散モデルは、データを潜在空間という抽象的な次元に変換し、その空間でノイズを扱いながらデータを生成する手法で、効率的に高品質な画像を生成するのに適している。
ここで可視化されている「ノイズ誤差」とは、AIが学習中に推定した出力と、実際に使用している学習サンプルとの間の誤差である。具体的には、AIは元の画像にノイズを加えて潜在空間にマッピングし、そのノイズを徐々に取り除いて元の画像を再構築しようとする。その過程で、推定した出力と学習サンプルとの違いが「誤差」として計算され、この誤差を減らすことで、AIがより正確に画像を生成できるように学習している。
この展示では、その「誤差」がどの程度発生しているかをリアルタイムで視覚化しており、AIが学習を進めるにつれて誤差がどのように減少していくかを観察できるようになっている。


②-c:Images generated by models from past to present(現在のモデルを用いた生成)
天王洲で展示されたアクリル作品と同じパラメータを使用して、AIモデルが学習100ステップごとに生成した画像を記録し、再生している。この映像はリアルタイムに更新されており、これにより、本モデルがどのようにして現在の出力を得るまでに変化していったのかを観察することができる。

②-d:Camera input video(カメラ入力映像)
屋外に設置したカメラからの画像のスルーアウトであり、このLEDに出力されている画像が、そのまま学習サンプルとして使用されている。
③ Generated Images

会期前半はBeyond Perception Model によって生成された画像のうち4枚を展示している。入力を変更して生成した 10 万枚の画像から真鍋が厳選したものからプリントして展示することで、モデルの出力の多様性と質の高さを示している。これらの画像は、従来の抽象絵画やジェネラティブアートとは異なるアプローチで生成され、独特の質感とパターンの融合を提示している。
会期後半では、学習プロセスを経て成長したAIモデルを用いて、新規に生成されたアクリルパネルが展示された。

④ Beyond Perception Model

本展覧会のベースとなっている、KOTARO NUKAGA(天王洲)で展示中のAIモデル「Beyond Perception Model」を本展でも参考展示している。
このAIモデルは、ライゾマティクスが手がけた映像の特徴や傾向を学習し、その独特の視覚的言語を模倣できる。具体的には、ライゾマティクス特有の色彩、形状、構成のパターンを理解し再現することに特化しており、これらの要素を組み合わせて新たなビジュアル表現を実質的には無限に生成可能である。また同時に、このモデルはライゾマティクスの視覚的アイデンティティを体現し、その創造的な遺産をデジタル世代に向けて拡張するツールとしても機能する。ユーザーはこのモデルを使って独創的な画像を生成し、鑑賞することができる。さらに、専門家や技術者はこのモデルを使用して、新たな作品やサービスを設計することができ、作品所有者にはそのライセンスも与えられる。
Beyond Perception Model 詳細:https://rhizomatiks.com/work/rhizomatiks-beyond-perception/
【展示歴】
2024
Sep 14 – Oct 03
at OMOTESANDO CROSSING PARK (Tokyo, Japan)
2025
Oct 06 – End of January 2026
at Kyoto University, Yoshida Campus, International Science Innovation Building (Kyoto, Japan)